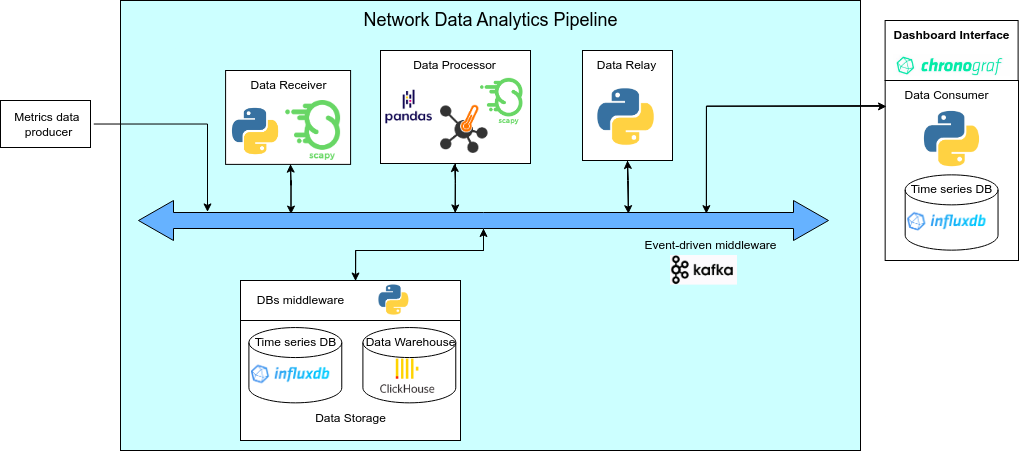
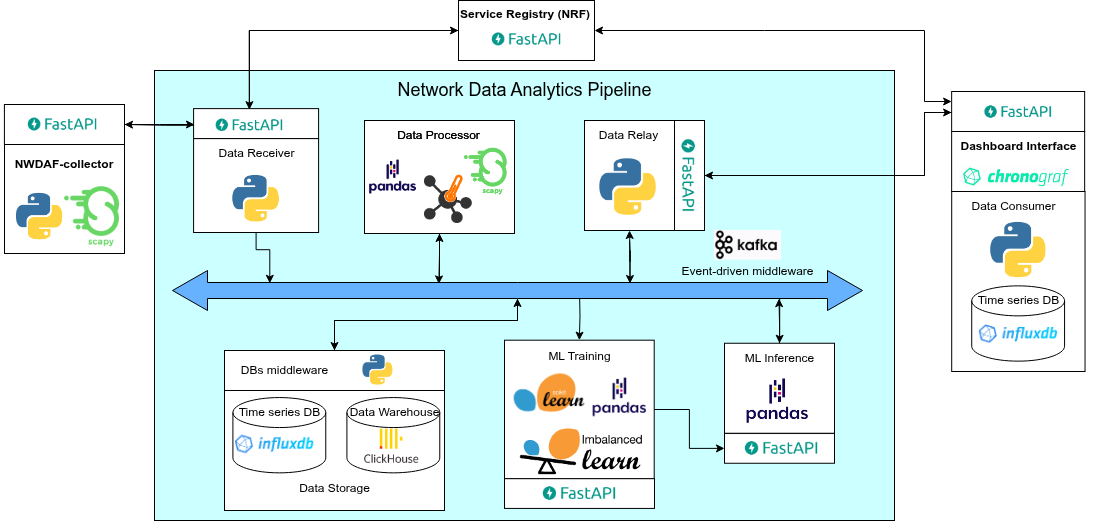
2025-04-22 00:13:51,510 - INFO - Model training complete.
2025-04-22 00:20:06,972 - INFO - Starting the ML pipeline...
2025-04-22 00:20:06,972 - INFO - Fetching new training data from ClickHouse...
2025-04-22 00:20:07,024 - INFO - Fetched 8210 rows and 46 columns
2025-04-22 00:20:07,024 - INFO - Preprocessing data...
2025-04-22 00:20:07,030 - INFO - Attack labels encoded: [' Fuzzers ', ' Reconnaissance ', 'Benign', 'DoS', 'Exploits', 'Generic']
2025-04-22 00:20:07,031 - INFO - Rows with Label = 1: 39
2025-04-22 00:20:07,031 - INFO - Final dataset shape after preprocessing: (8210, 43)
2025-04-22 00:20:07,031 - INFO - Training and comparing classifiers...
2025-04-22 00:20:07,034 - INFO - Training Random Forest...
2025-04-22 00:20:07,299 - INFO -
--- Classification Report: Random Forest ---
2025-04-22 00:20:07,303 - INFO -
precision recall f1-score support
1 0.00 0.00 0.00 1
2 1.00 1.00 1.00 1636
4 1.00 0.20 0.33 5
accuracy 1.00 1642
macro avg 0.67 0.40 0.44 1642
weighted avg 1.00 1.00 1.00 1642
2025-04-22 00:20:07,303 - INFO - Training Gradient Boosting...
2025-04-22 00:20:14,447 - INFO -
--- Classification Report: Gradient Boosting ---
2025-04-22 00:20:14,451 - INFO -
precision recall f1-score support
0 0.00 0.00 0.00 0
1 0.00 0.00 0.00 1
2 1.00 1.00 1.00 1636
4 1.00 0.40 0.57 5
accuracy 1.00 1642
macro avg 0.50 0.35 0.39 1642
weighted avg 1.00 1.00 1.00 1642
2025-04-22 00:20:14,451 - INFO - Training MLP (Neural Network)...
2025-04-22 00:20:14,639 - INFO -
--- Classification Report: MLP (Neural Network) ---
2025-04-22 00:20:14,644 - INFO -
precision recall f1-score support
1 0.00 0.00 0.00 1
2 1.00 1.00 1.00 1636
4 0.00 0.00 0.00 5
accuracy 1.00 1642
macro avg 0.33 0.33 0.33 1642
weighted avg 0.99 1.00 0.99 1642
2025-04-22 00:20:14,645 - INFO - Model training complete.