Architecture
Diagram
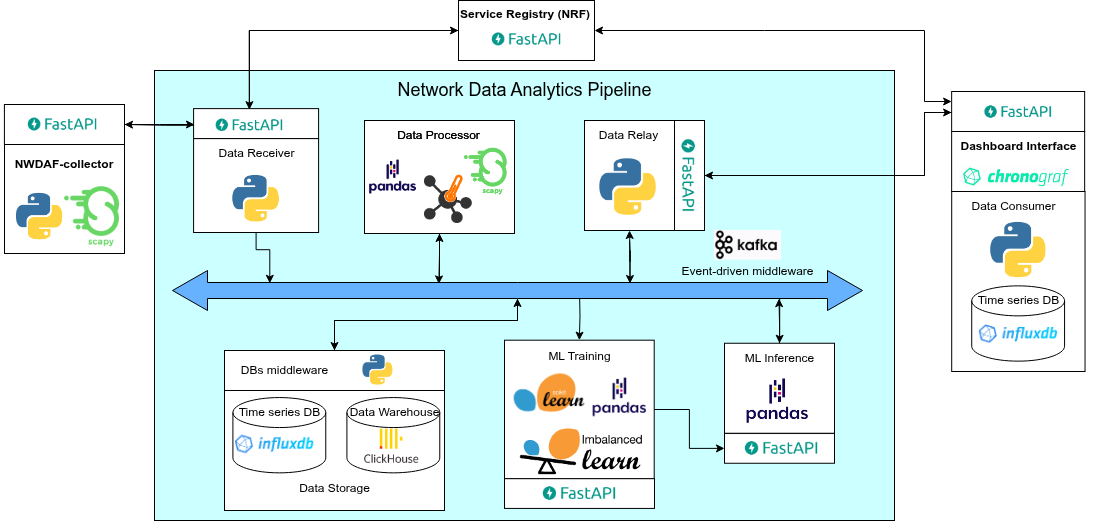
Components and its interactions
Event-driven middleware: Kafka
The primary way to ensure the pipeline’s modules can communicate is by using an event-driven middleware, where the modules can publish data on the appropriate topics. This way, all communication through the middleware is asynchronous. With this approach, every time new data is available to be used by a certain module, it will consume the data in the corresponding topic automatically (the middleware moves the data as close to real-time as possible). Therefore, the middleware acts as an intermediary between different pipeline components, assuring that the modules are decoupled, which is fundamental to ensure reduced interdependence between the system’s components and reliable event processing (very important for our pipeline). This separation enhances the system’s adaptability, maintainability, and scalability by allowing individual parts to be modified without significantly impacting others.
So, the middleware was implemented using Kafka. We chose this technology because it is designed to handle large volumes of data, has low latency, and is highly used in event-driven architectures (architecture shown in the previous figure). Kafka is also excellent for transmitting data in real-time for ML applications such as forecasting and model monitoring. This technology is great for environments where data size growth is high, as it can be scaled horizontally and guarantees message durability (data retention for a defined time). The architecture of this technology also offers great fault tolerance, which is important for our solution, since no message sent between services must be lost.
APIs: FastAPI
In our proposed architecture, both APIs and Kafka play essential and complementary roles in enabling reliable, scalable, and modular communication between the various components of the MLOps pipeline. As the system is designed to operate in real-time and handle high-throughput network data, Kafka serves as a robust, event-driven middleware for decoupling services and efficiently managing streaming data between producers and consumers. Kafka ensures that the pipeline can ingest and process continuous data streams with high availability and fault tolerance.
On the other hand, well-defined APIs are necessary for service orchestration, external system integration, and exposing internal functionality in a controlled and standardized manner. APIs are used in several ways: to enable external systems or network components to push data into the pipeline; to allow various internal modules to invoke each other’s functionality; and to make pipeline outputs, such as inference results, accessible to other NFs. Following RESTful principles and contract-driven design practices ensures long-term maintainability and interoperability of these interfaces.
FastAPI is a modern web framework that is fast and used to build APIs in Python and which automatically produces documentation of the implemented APIs (OpenAPI and Swagger). This framework is simple and easy to use, reducing development and maintenance time. It is also important to note that it is compatible with Pytorch and Scikit-learn, facilitating integration into MLOps pipelines. FastAPI is therefore an efficient and fast way to produce APIs, without wasting time documenting them.
NWDAF Collector: Scapy
In the early stages of pipeline development, it is essential to have a controlled and reproducible environment for testing the system’s ability to ingest, process, and analyze real-world traffic. To meet this requirement, we developed a custom NWDAF collector that simulates the behavior of a 5GC network function. This module serves as the primary entry point for data into our pipeline, playing a vital role in feeding raw network traffic into the system for further processing and analysis.
The NWDAF collector is responsible for supplying the pipeline with realistic network packets by reading from a dataset composed of multiple .pcap files. These packet capture files contain actual recorded traffic captured in various network scenarios. To extract and manipulate this packet data, the NWDAF collector leverages Scapy, a powerful Python library used for crafting, parsing, and analyzing network packets. Scapy excels at dissecting packet headers, reconstructing protocol stacks, and extracting metadata required by downstream components. In this context, Scapy is used to interpret the contents of the .pcap files. The flexibility of Scapy allows the collector to simulate complex traffic patterns with possible attack information.
Once the packets are parsed and prepared, the NWDAF collector exposes this raw traffic data through a FastAPI interface, ensuring seamless integration with the pipeline’s data ingestion component (Data Receiver).
Data Receiver and Data Relay: Python
To ensure seamless communication between the pipeline and the 5GC, two critical components were developed: the Data Receiver and the Data Relay. These modules serve as the primary input and output interfaces of the system, enabling bidirectional integration with NFs and external services.
The Data Receiver is responsible for ingesting data from the 5GC. It acts as a listening service, exposed via a FastAPI endpoint, that receives incoming data from various 5G NFs. These payloads, often structured in JSON format and aligned with 3GPP-compliant data models, are immediately pushed to Kafka topics for downstream consumption. This design ensures that as soon as a core function exposes network data, it is received by the pipeline in near real time and made available to the processing and ML modules. Python was chosen to implement this service due to its simplicity and strong ecosystem support for working with network data and asynchronous APIs. On the other side of the pipeline, the Data Relay is responsible for exposing processed data and inference results back to the 5GC or any other consumer system. This component formats and serves the analytics output through another FastAPI interface. By exposing these results via RESTful endpoints, the Data Relay enables external NFs, dashboards, or orchestration tools to access live insights generated by the ML models and the data processor. The use of Kafka ensures that all outgoing data is decoupled from upstream processing, maintaining system flexibility and scalability.
Together, the Data Receiver and Data Relay form the external communication boundary of the pipeline. They ensure that the system remains interoperable, standards-compliant, and capable of operating in real 5G network environments. Both are lightweight Python services, easy to deploy and maintain, and tightly integrated into the event-driven flow of the pipeline.
Data processor: Pandas, nProbe, and Scapy
The data processor is a key component of our pipeline, responsible for transforming raw traffic data collected from the network into clean, structured, and enriched information that can be used by downstream modules and external systems. Most network data is not directly usable in its raw form, especially for tasks like training ML models or feeding analytics dashboards. This module ensures that the incoming traffic (often noisy, unstructured, and high-volume) is parsed, filtered, and converted into valuable insights. To accomplish this, our data processor uses a combination of Scapy, nProbe, and Pandas.
We integrate nProbe, a high-performance flow exporter and collector that converts packet-level data into rich flow-level metadata. nProbe is used to extract NetFlow features, which are essential for understanding traffic behavior at an aggregated level. These features include flow duration, number of packets and bytes exchanged, TCP flag summaries, average packet size, flow directionality, protocol distribution, and inter-arrival times. By exporting this information in NetFlow or IPFIX formats, nProbe adds semantic meaning and behavioral context to the data, which is essential for tasks like anomaly detection, traffic classification, and usage profiling. Additionally, nProbe supports advanced traffic analysis capabilities such as application protocol recognition through deep packet inspection (DPI), TLS fingerprinting, and classification using NBAR2, all of which enrich the dataset used downstream.
Once data is parsed and enriched, it is structured and prepared for analytics using Pandas, a widely adopted data analysis library in Python. Pandas provides a robust set of tools for cleaning, transforming, and aggregating structured data. In our pipeline, Pandas handles missing values, normalizes data formats, creates aggregated views (e.g., per-user, per-flow, or per-network slice), and encodes features suitable for ML models. With its powerful DataFrame abstraction and interoperability with the rest of the data science ecosystem, Pandas enables efficient data wrangling and fast prototyping of ML-ready datasets.
Data storage: influxDB and ClickHouse
It is a requirement of the project that our pipeline stores the data instead of using an external service. So, to accommodate this necessity, we have a data storage module where all data is kept on-premise. This module has a middleware and two databases. The middleware agent is responsible for fetching the data present in the event-driven middleware (Kafka), and deciding in which database it should store them. This decision is made according to the nature of the data. The raw data fetched from the 5G core network functions is stored in our time series database (influxDB) and the processed data is stored in the data warehouse (ClickHouse).
-
InfluxDB is a high-performance, open-source time series database. It is optimized to handle high write rates and real-time analysis, making it ideal for use cases such as IoT sensor data and monitoring. It also has a query language similar to SQL but specified for time series data. In this way, influxDB is an excellent choice to integrate into our pipeline and use as the main source of storage for data received from the network, since this data comes from IoT sensors and there is great importance in maintaining the chronological order of the time record in which it was collected.
-
ClickHouse is an open-source column-oriented database that stands out for its high performance as a data warehouse for storing analytical and time series data. It has a query language similar to SQL and is optimized for high-speed queries on large data sets, making it an excellent choice for analyzing large volumes of data. It is also important to mention its efficient storage with advanced compression techniques, which reduce the cost of storage (something crucial when working with large volumes of data). Therefore, ClickHouse is the perfect choice for storing processed data, ready to be used to train the ML model, and data from the model's inference, which is then distributed to data consumers.
ML training and inference: Scikit-learn and Imbalanced-learn
To ensure accurate and reliable model predictions, our pipeline includes a dedicated ML training and inference module. This component is responsible for training and testing ML models using the processed data stored in the data warehouse (ClickHouse) before the models are deployed for real-time inference.
For the initial version of the pipeline, we chose to use Scikit-learn and Imbalanced-learn, both of which are robust and mature Python libraries suitable for building classical ML solutions. These technologies offer a solid foundation for supervised and unsupervised learning tasks such as classification, regression, and clustering, all of which are critical in network data analytics.
Scikit-learn is an open-source ML library built on top of NumPy, SciPy, and Matplotlib. It includes a wide range of efficient tools for ML and statistical modeling, including support vector machines, random forests, gradient boosting, k-means, and more. Its ease of use, extensive documentation, and integration with other Python libraries make it an ideal choice for prototyping and deploying models in production.
Imbalanced-learn is a complementary library that provides techniques specifically designed for imbalanced datasets, which are common in real-world network traffic (e.g., rare failure events or anomalies). It supports resampling methods such as SMOTE (Synthetic Minority Over-sampling Technique), undersampling, and combined strategies that help improve model performance on skewed datasets.
By using these two libraries together, we ensure the development of balanced, high-performing models that are well suited for network traffic prediction and anomaly detection. These models are then deployed via FastAPI, making their predictions available in real-time to other components in the pipeline or external consumers.
Dashboard interface: Chronograf
Before trying to integrate the pipeline in the 5G core network, we need to simulate the behavior of a network function that would consume the data produced by our pipeline (process and inference data) so we can validate it. The easiest way to visualize this data is to use a dashboard where we can display all the metrics. Instead of wasting time building a dashboard from scratch, we can use technologies that make the process easier and faster. So, on that note, we decided to use Chronograf developed by InfluxData.
Chronograf is a data visualization and monitoring tool used to analyze various metrics and records obtained in real-time. It offers a complete dashboarding solution for visualizing data. With it, we can easily clone a pre-canned dashboard (over 20 pre-canned dashboards). This saves a lot of development time since you don't have to make a complete interface from scratch with a specialized framework. Chronograf allows us to use Flux or the InfluxQL queries to fetch and analyze data. This tool makes it easy to develop dynamic and customizable interfaces without a great deal of effort and time, making it the perfect choice for simulating the operation of a 5G core network function that consumes the data provided by the pipeline.